Couchbase¶
Couchbase is a highly acclaimed distributed NoSQL cloud database known for its exceptional flexibility, performance, scalability, and cost-effectiveness, making it ideal for cloud, mobile, AI, and edge computing applications.
Vector Search is a part of the Full Text Search Service (Search Service) in Couchbase.
You can apply these with both Couchbase Capella and a self-managed Couchbase Server.
Configuration¶
This guide will fit Couchbase Capella UI. If you are using a self-managed Couchbase Server, you can see here.
To use the Couchbase vector database, you need to configure it in your YAML configuration file.
First, you need to set the Couchbase cluster connection information.
Edit Cluster Access¶
Set Access username, password and connection_string for the Couchbase cluster.
And set bucket, scope and access level(Read/Write) for the Couchbase cluster.
Allowed IP Addresses¶
You need to allow the IP address of the VectorDB server in the Couchbase cluster.
Cluster, Bucket, Scope, Collection¶
Cluster, Bucket must be prepared in advance.
Scope and Collection should be prepared in advance, otherwise they will be created automatically.
Create Index for Query¶
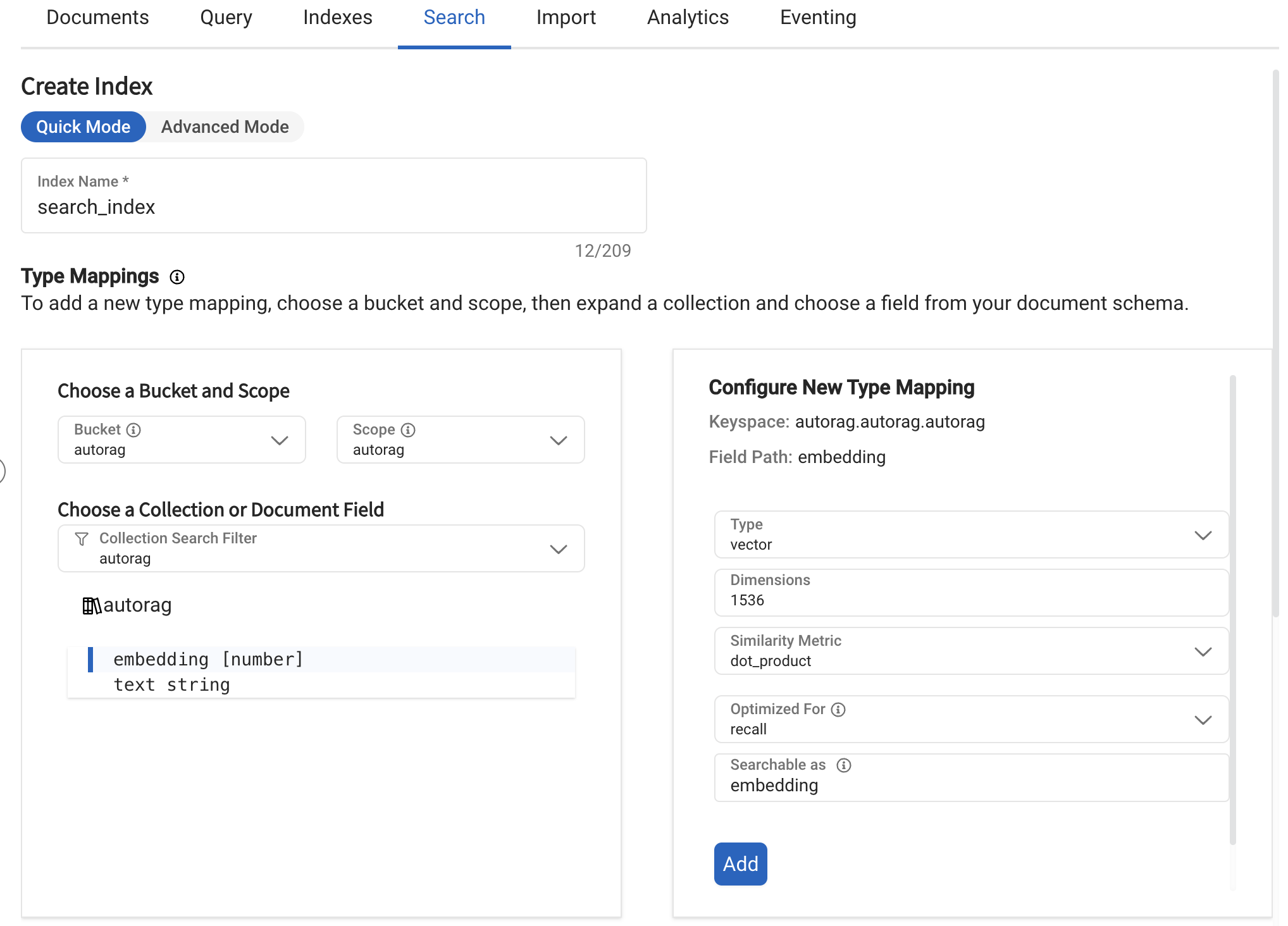
This should correspond to the dimension of the embeddings generated by the specified embedding model.
Example YAML file¶
- name: openai_couchbase
db_type: couchbase
embedding_model: openai_embed_3_large
bucket_name: autorag # replace your bucket name
scope_name: autorag # replace your scope name
collection_name: autorag # replace your collection name
index_name: autorag_search # replace your index name
connection_string: ${COUCHBASE_CONNECTION_STRING}
username: ${COUCHBASE_USERNAME"}
password: ${COUCHBASE_PASSWORD"}
Here is a simple example of a YAML configuration file that uses the Couchbase vector database and the OpenAI:
vectordb:
- name: openai_couchbase
db_type: couchbase
embedding_model: openai_embed_3_large
bucket_name: autorag # replace your bucket name
scope_name: autorag # replace your scope name
collection_name: autorag # replace your collection name
index_name: autorag_search # replace your index name
connection_string: ${COUCHBASE_CONNECTION_STRING}
username: ${COUCHBASE_USERNAME"}
password: ${COUCHBASE_PASSWORD"}
node_lines:
- node_line_name: retrieve_node_line # Arbitrary node line name
nodes:
- node_type: retrieval
strategy:
metrics: [retrieval_f1, retrieval_recall, retrieval_precision]
top_k: 3
modules:
- module_type: vectordb
vectordb: openai_couchbase
- node_line_name: post_retrieve_node_line # Arbitrary node line name
nodes:
- node_type: prompt_maker
strategy:
metrics: [bleu, meteor, rouge]
modules:
- module_type: fstring
prompt: "Read the passages and answer the given question. \n Question: {query} \n Passage: {retrieved_contents} \n Answer : "
- node_type: generator
strategy:
metrics: [bleu, rouge]
modules:
- module_type: llama_index_llm
llm: openai
model: [ gpt-4o-mini ]
Parameters¶
embedding_model: strPurpose: Specifies the name or identifier of the embedding model to be used.
Example: “openai_embed_3_large”
Note: This should correspond to a valid embedding model that your system can use to generate vector embeddings. For more information see custom your embedding model documentation.
embedding_batch: int = 100Purpose: Determines the number of embeddings to process in a single batch.
Default: 100
Note: Adjust this based on your system’s memory and processing capabilities. Larger batches may be faster but require more memory.
bucket_name: strPurpose: Specifies the name of the bucket where the vectors will be stored.
Example: “my_bucket”
Note: Bucket must be prepared in advance.
scope_name: strPurpose: Specifies the name of the scope where the vectors will be stored.
Example: “my_scope”
Note: If the scope doesn’t exist, it will be created. If it exists, it will be loaded.
collection_name: strPurpose: Specifies the name of the collection where the vectors will be stored.
Example: “my_collection”
Note: If the collection doesn’t exist, it will be created. If it exists, it will be loaded.
index_name: strPurpose: Specifies the name of the Couchbase index to be used for querying.
Example: “my_vector_index”
Note: Index must be prepared in advance.
connection_string: strPurpose: Specifies the connection string for the Couchbase cluster.
Note: This should be the connection string for your Couchbase cluster.
username: strPurpose: Specifies the username for authentication with the Couchbase cluster.
Note: This should be the username for your Couchbase cluster.
password: strPurpose: Specifies the password for authentication with the Couchbase cluster.
Note: This should be the password for your Couchbase cluster.
ingest_batch: int = 100Purpose: Determines the number of vectors to ingest in a single batch.
Default: 100
Note: Adjust this based on your system’s memory and processing capabilities. Larger batches may be faster but require more memory.
text_key: str = "text"Purpose: Specifies the key in the document where the text data is stored.
Default: “text”
Note: This should correspond to the key in the document where the text data is stored.
embedding_key: str = "embedding"Purpose: Specifies the key in the document where the vector embeddings are stored.
Default: “embedding”
Note: This should correspond to the key in the document where the vector embeddings are stored.
scoped_index: bool = TruePurpose: Specifies whether the index is scoped to the collection.
Default: True
Note: If True, searches in the scope. If False, searches across the entire cluster.
Usage¶
Here’s a brief overview of how to use the main functions of the Couchbase vector database:
Adding Vectors:
await couchbase_db.add(ids, texts)
This method adds new vectors to the database. It takes a list of IDs and corresponding texts, generates embeddings, and inserts them into the Couchbase Collection.
Querying:
ids, scores = await couchbase_db.query(queries, top_k)
Performs a similarity search on the stored vectors. It returns the IDs and their scores. Below you can see how the score is determined.
Fetching Vectors:
vectors = await couchbase_db.fetch(ids)
Retrieves the vectors associated with the given IDs.
Checking Existence:
exists = await couchbase_db.is_exist(ids)
Checks if the given IDs exist in the database.
Deleting Vectors:
await couchbase_db.delete(ids)
Deletes the vectors associated with the given IDs from the database.