Road to Modular RAG¶
🤷♂️ What is Modular RAG?¶
In a survey paper about RAG, they propose three paradigms of RAG.
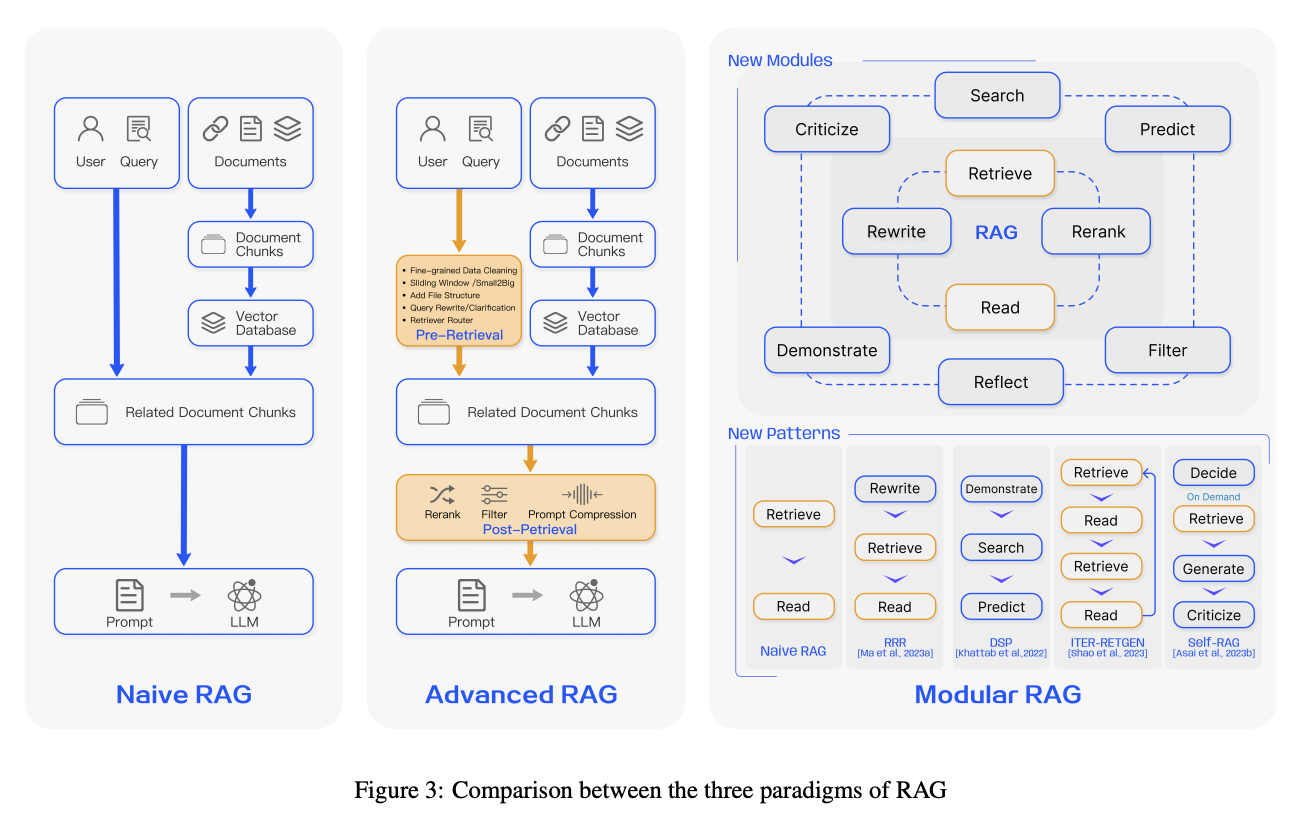
At first, Naive RAG is a simple RAG paradigm. It embeds document chunks to Vector DB and retrieves using a user query and generates an answer with that retrieved document chunk.
You can build Naive RAG really easily these days. All you need is the following tutorial of Langchain or LlamaIndex, or other RAG frameworks out there. However, there are performance issues with Naive RAG. If you ever try Naive RAG, you know the performance can be bad in real use-cases.
So, here comes the second paradigm, Advanced RAG. Advanced RAG supports a few pre-retrieval and post-retrieval features, like reranking, query expansion, and so on. It is more powerful than Naive RAG, but still it is not perfect.
The main problem of Advanced RAG is that it still doesn’t have cycles. Why are cycles important?
For example, the LLM model generates an answer, but it has hallucination about facts. If that answer delivers to the user, the user gets wrong information, and it occurs the bad user experience. To prevent this, we need to check the answer’s fatefulness. And if there is a hallucination you can ask the generator to re-generate the answer or retrieve the document chunk again. In a DAG paradigm like Naive RAG & Advance RAG, it is impossible to do that because they don’t have cycles. And here comes Modular RAG.
Modular RAG has cycles and modules, so it can decide the next step to deliver the best answer to the user.
Want to know more about Modular RAG?
Recommend to read the survey paper.
🚀 Road to Modular RAG¶
In this version of AutoRAG, we support Advanced RAG only.
However, we know how Modular RAG is important to RAG pipelines, so we’re planning to support Modular RAG ASAP.
Let me explain our plan to implement Modular RAG.
Early version of AutoRAG¶

Here is a simple diagram of Advanced RAG. Think of each circle as a node. User query goes to retriever, retrieves document chunk, and rerank, make prompt and generate answer.
You can build this kind of pipeline with AutoRAG easily from now.
Tip
If you don’t know yet how to build pipeline and optimize it, please see optimization guide.
Policy Node¶
Warning
This document is about our plan, so it can be changed in the future.
Also, it is not implemented to AutoRAG yet.
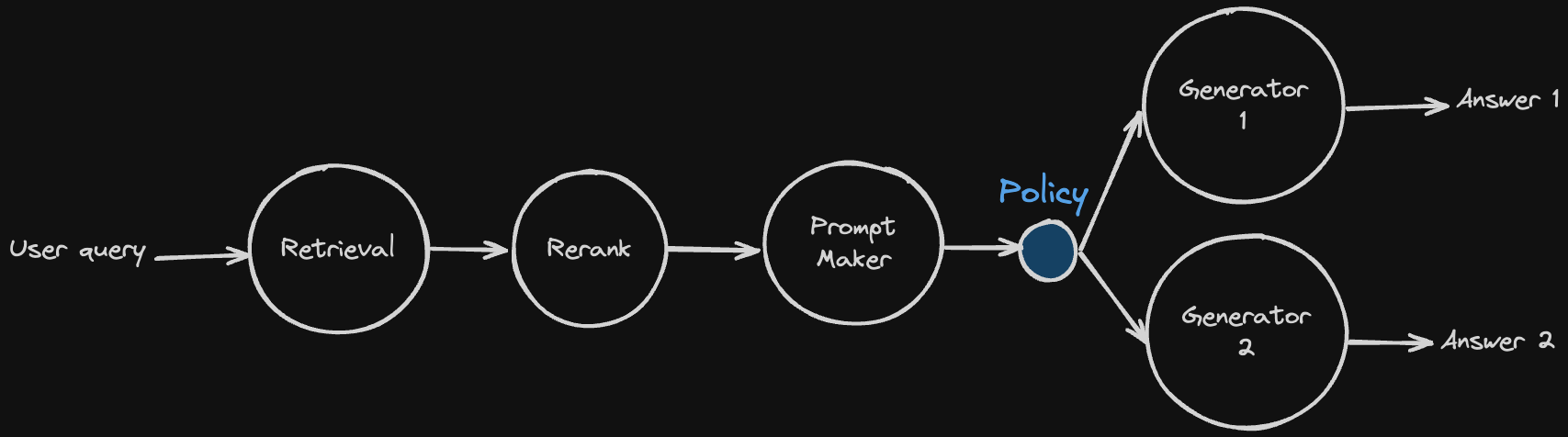
We’re planning to add a new node, Policy Node. Can you see the little blue node in the diagram? That is the policy node. It gets a previous result from previous nodes and decides the next step based on that result.
In this example, the policy gets prompt and selects which Generator model is good for generating the final answer.
Merger Node¶
There is a limitation of the policy node that it can’t merge the results again.
Once policy takes its action, it can’t merge the results again without Merger Node.
With the merger node, we can now create cycles in the RAG pipeline.
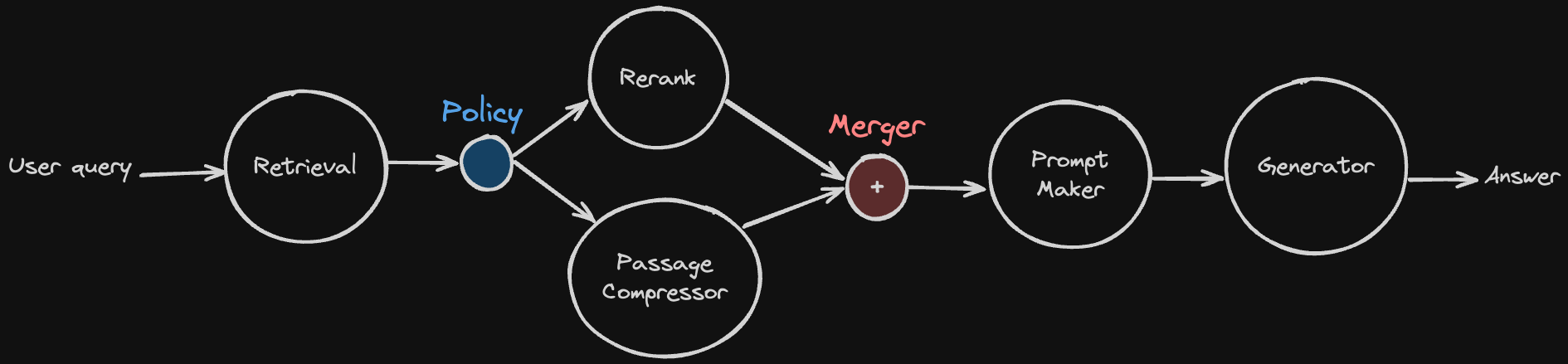
Here is a diagram that used Merger node.
At first, there is a policy that gets retrieved document chunks as input.
It decides to rerank it or just compress long document chunks to short passage.
After that, it must pass to a single prompt maker node.
And then, here comes Meger Node.
It gets the result from multiple nodes and passes it to the next node.
In this way, the prompt maker node gets passages to make a prompt, no matter how the policy node decides.
So, how can make cycle with Merger Node?
Let me show you an example.

Pretty good, right? The policy in the above diagram decides a reranked result passed to the prompt maker for generation, or request to retrieve again. At a merger located before the retrieval node, it gets the user query and passed to the retrieval node.
Voilà! We made a cycle in the RAG pipeline.
But we have a problem implementing this to AutoRAG.
How can we make this to a single YAML file?
How can we make complex Modular RAG pipelines using the YAML file alone?
Node line for Modular RAG¶
The solution is Node Line.
If you learned about structure of AutoRAG config file, you’re familiar with Node Line.
What is Node Line?
If you are not familiar with Node Line, please see optimization guide.
In the Advanced RAG, Node line is like a folder. There is no much feature on it, just a collection of nodes.
But think of this way. A single Node line is like a straight line. It is a linear structure. It doesn’t have any branches or cycles.
And the magic happens as a policy node and merger node only. You can type which node line can be the next step at the policy node. If the node line is the target of the policy, you must set a merger node to merge the results from the node line.
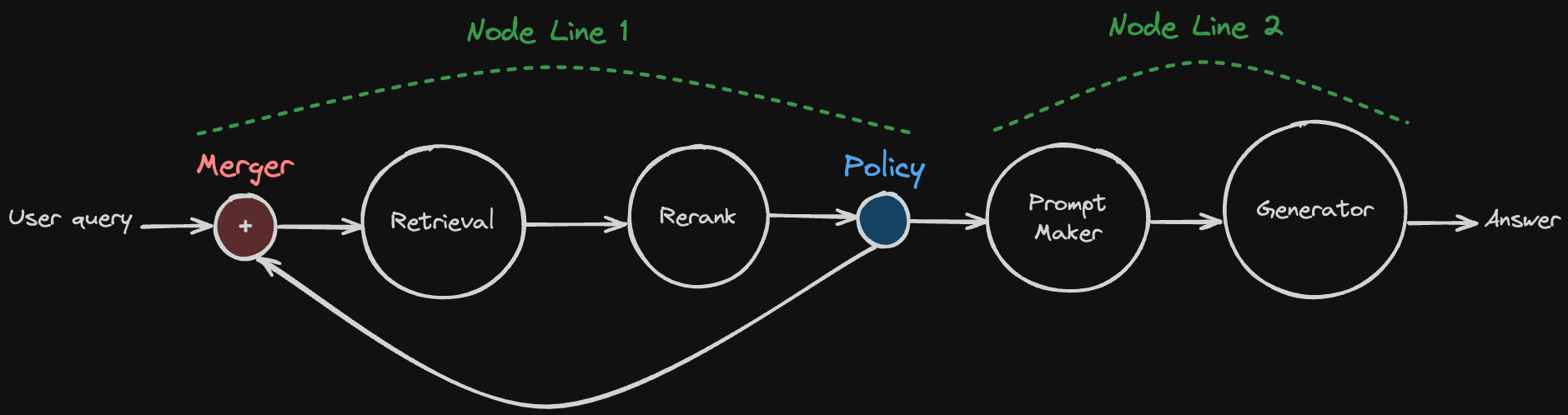
In the above diagram, I made two node lines to implement the cycle. You can write your config YAML file to make the above pipeline like below.
node_lines:
- node_line_name: node_line_1
nodes:
- node_type: merger
pass_value: query
- node_type: retrieval
strategy:
metrics: [retrieval_recall]
top_k: 10
modules:
- module_type: bm25
- node_type: passage_reranker
strategy:
metrics: [reranker_recall]
top_k: 3
modules:
- module_type: upr
- node_type: policy
target_node_lines:
- node_line_1
- node_line_2
modules:
- module_type: kf1_policy
- module_type: rl_policy
- node_line_name: node_line_2
nodes:
- node_type: prompt_maker
modules:
- module_type: fstring
prompt: "Answer the question: {query} \n\n Passage: {retrieved_contents}"
- node_type: generator
strategy:
metrics: [bleu, rouge, meteor]
modules:
- module_type: llama_index_llm
llm: openai
Looks cool, right?
Contact us¶
We’re tyring hard to make Modular RAG at AutoRAG as soon as possible.
If you’re really interested in Modular RAG, feel free to contact us.
We’re welcoming any questions, suggestions, feature requests, feedback, and so on.
Contact
Github Issue : https://github.com/Marker-Inc-Korea/AutoRAG/issues
Discord : https://discord.gg/P4DYXfmSAs